Klotzkopp
User
-
Registriert
-
Letzter Besuch
Alle Beiträge von Klotzkopp
-
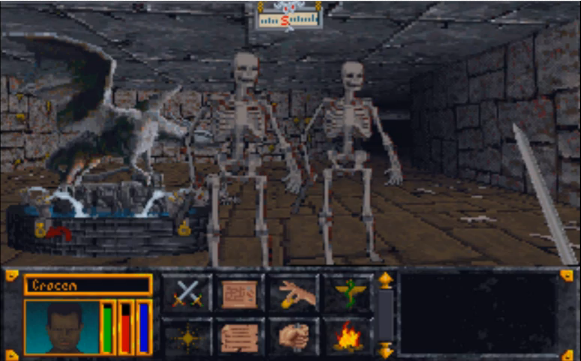
Richtig
-
Bitteschön:
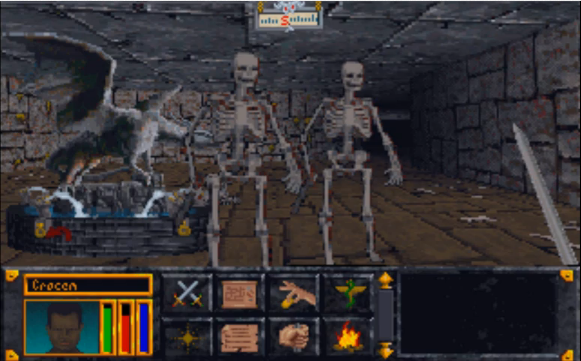
-
Erinnert mich an Impossible Mission.
-
Richtig
-
Auch nicht. Es ist aber wie The Bard's Tale Teil einer Reihe, in diesem Fall der zweite.
-
Es ist nicht Loom. Brutzeln muss man aber im Spiel auch nicht, das Bild ist aus dem Abspann.
-
Lands of Lore ist schon nah dran, was Gameplay angeht, aber nicht richtig.
-
Na dann:

-
Sieht aus wie Gauntlet. Gab's das für PC? Edit: Offenbar ja.
-
Nein, nicht Cache. Ich habe den Anhang zwischenzeitlich freigeschaltet.
-
Wikipedia.
-
Da die meisten Spieler nur begrenzt Zeit haben, werden sich diese auf die am schnellsten zu besiegenden Bosse beschränken. Und wer rund um die Uhr spielen kann, hat nach 2 Wochen alles beisammen und langweilt sich. Wolltest du nicht eben noch alles gleich schwer machen und die Drops überall verteilen?
-
Dann werden alle nur noch den schnellsten Boss farmen. Der Effekt wäre also das genaue Gegenteil.
-
Wenn dort = stünde, ja. Aber genau das will man ja rausfinden: Bei welcher Anzahl sind die Kosten gleich. Und da muss man schon identische Anzahlen verwenden. Wenn du sowieso deine Variablen hinterher gleichsetzt, kannst du auch gleich nur eine benutzen Der Ansatz mit der Ungleichung ist mathematisch genau richtig. Allerdings ist es mit einer Ungleichung etwas schwieriger, die algebraischen Umformungen richtig durchzuführen. Wenn man MikeX' Ungleichung umformt, kommt man auf x > 40, also genau die richtige Lösung. Beim Gleichsetzen müsste man noch ausprobieren, auf welcher Seite des Kostenschnittpunkts das Nachfüllen günstiger ist.
-
Sieht gut aus. Was meinst du mit "InternetRechner"? Wenn man keinen Taschenrechner hat, benutzt man eben schriftliche Division.
-
Äh, was? Rechne bitte Länge und Breite getrennt um. Sonst musst du Quadratzentimeter in Quadratzoll umrechen.
-
Du weißt, wieviele Zentimeter ein Zoll hat. Und du weißt, wieviele Pixel pro Zoll das Bild hat. Also kannst du die cm zu Zoll und dann die Zoll zu Pixeln umrechnen. Das machst du für die Höhe und Breite. Dann kannst du ausrechnen, wieviele Pixel das Bild hat. Und da du weißt, wieviel Speicher 1 Pixel braucht, kannst du daraus berechnen, wieviel Speicher das ganze Bild braucht.
-
Du musst den Code compilieren, bevor du Objekte erzeugen kannst.
-
Bitte schildere das tatsächliche Problem, nicht deine Interpretation, oder was du für die Ursache hältst. Was machst du genau? Was ist das erwartete Verhalten der Software? Was ist das beobachtete Verhalten der Software?
-
Etwas ausführlicher: So kann man das rechnen. Man kann die Beschreibung von Variante B aber auch so auffassen, dass unabhängig von der Gesamtanzahl an Lizenzen die ersten zehn 105 Euro kosten, die nächsten 90 75 Euro usw.: 10 * 105 Euro (Lizenzen 1 bis 10) 90 * 75 Euro (Lizenzen 11 bis 100) 150 * 40 Euro (Lizenzen 101 bis 250) 250 * 10 Euro (Installation) Summe: 16.300 Euro
-
Ich komme bei A auch auf 17.790. Allerdings komme ich bei B auf 16.300. Vermutlich sind 16.300 und 12.500 die möglichen Werte für Variante B, je nachdem, ob man die günstigeren Preise für alle Lizenzen rechnet oder nicht. Und da nur nach den Kosten für die günstigere Variante gefragt war, taucht A gar nicht als Lösungmöglichkeit auf.
-
Wer die Linkliste ergänzen möchte, stelle bitte einfach einen neuen Beitrag hier ein. Ich werde von Zeit zu Zeit die Links in den ersten Beitrag einpflegen. Falls das mal etwas länger dauern sollte, bitte eine PN an mich
-
Wenn du schon einen Parser hast, dann solltest du als nächstes einen Algorithmus zum Auflösen nach x formulieren. Vielleicht solltest du dich dabei zunächst auf Ausdrücke beschränken, in denen nur ein x auftaucht, damit du nur mit linearen Gleichungen zu tun hast. Sonst könnte dir auch die eine oder andere quadratische begegnen.
-
Das ist das Travelling Salesman Problem (wenn man die Rückkehr zum Startpunkt weglässt). Bisher ist kein Algorithmus bekannt, der das Problem schneller als exponentiell löst. Du kannst natürlich alle möglichen Routen durchprobieren, aber bei vielen Punkten wird das sehr bald sehr langsam. Um wieviele Punkte geht es denn?
-
Nur wenn die Leiter genau 2 * Wurzel aus 2 Meter lang ist, gibt es genau eine Lösung, nämlich 2 Meter.